.png)

AI ML infrastructure is quickly approaching a breaking point due to the limited supply of critical compute resources that keep this innovative industry moving. Traditional Big Tech cloud providers are failing to meet the demand required by modern AI applications. They currently have 2.5x less capacity than the estimated demand, which is creating bottlenecks and restricting access to these essential resources needed by teams building in the space.
Companies switching to io.net's distributed network report cutting their monthly training costs by up to 90%. They're deploying clusters in under 2 minutes instead of waiting weeks for AWS capacity to open up.
Fortunately, this infrastructure dilemma has created an opportunity for distributed architecture to emerge. It is quickly establishing itself not only as a viable alternative but also as a catalyst for a wholesale technological paradigm shift that can democratize access to GPU resources while also improving its overall cost and performance. io.net is leading the charge of this distributed architecture overhaul through its novel DePIN solution of aggregating underutilized computing power from independent data centres, crypto miners, and distributed networks.
What is ML Infrastructure?
ML infrastructure refers to the hardware, software, networking, and operational components required for the data processing, model training, inference, and deployment of AI ML applications across distributed networks. Effectively, ML infrastructure is the entire tech stack that is required to enable machine learning applications to operate at scale.
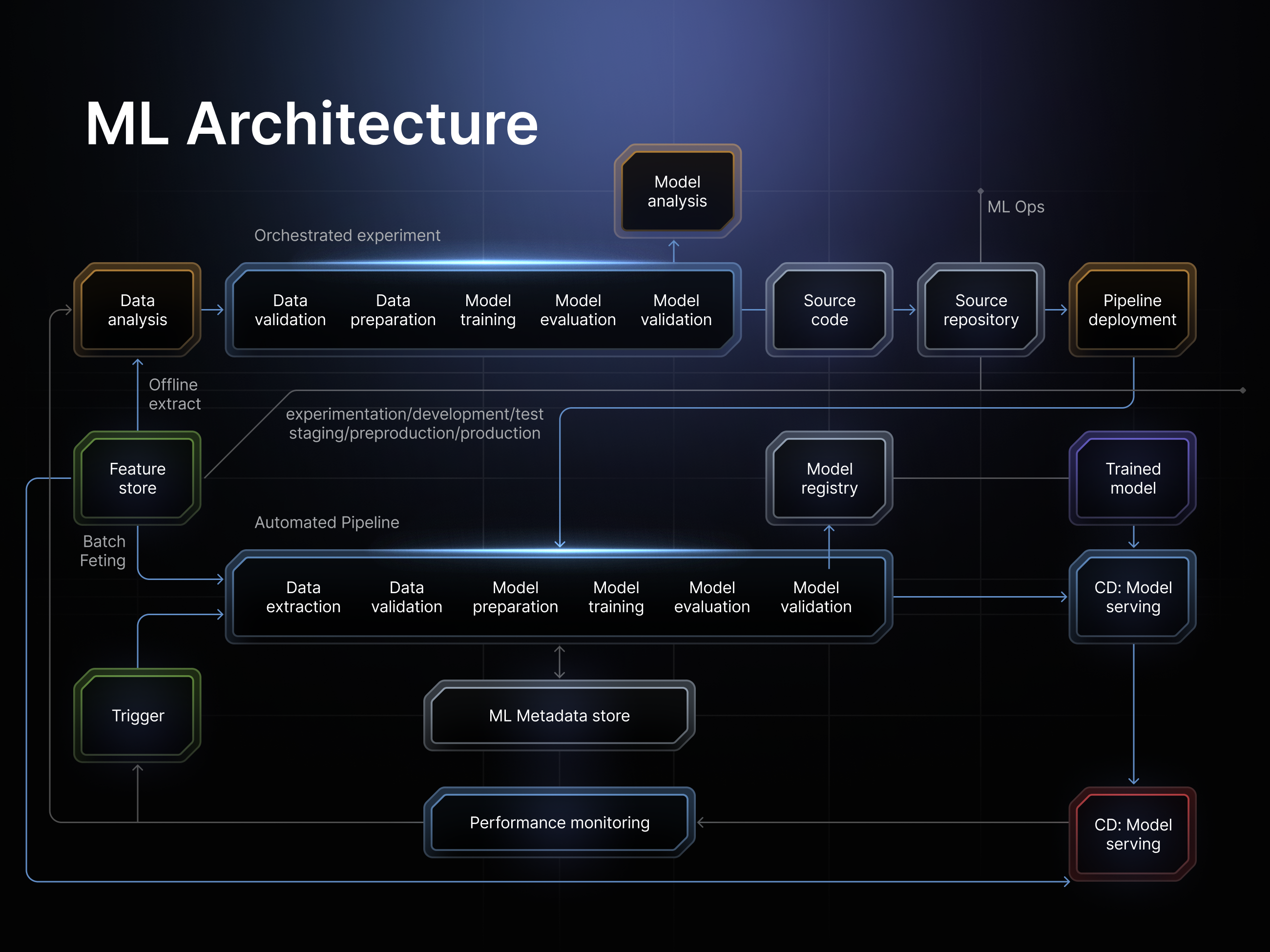
Distributed architecture is uniquely positioned to improve the efficiency and performance of both cloud and on-premise ML infrastructure providers, while solving their most significant issues.
Cloud vs On-Premise ML Infrastructure
Big Tech cloud infrastructure providers like AWS, Azure, and the Google Cloud Platform have historically enabled easy scalability and helped reduce overhead for ML applications. However, the reason they have been able to achieve this success is by concentrating critical computing resources into massive centralized data centers. This enabled them to establish large moats of access to essential compute resources, which has allowed them to artificially constrain supply and create vendor lock-in at premium pricing. Comparatively, on-premise solutions allow for more ownership and control over these resources, but they require significant upfront costs and ongoing maintenance, making them prohibitively expensive for most applications building in the space.
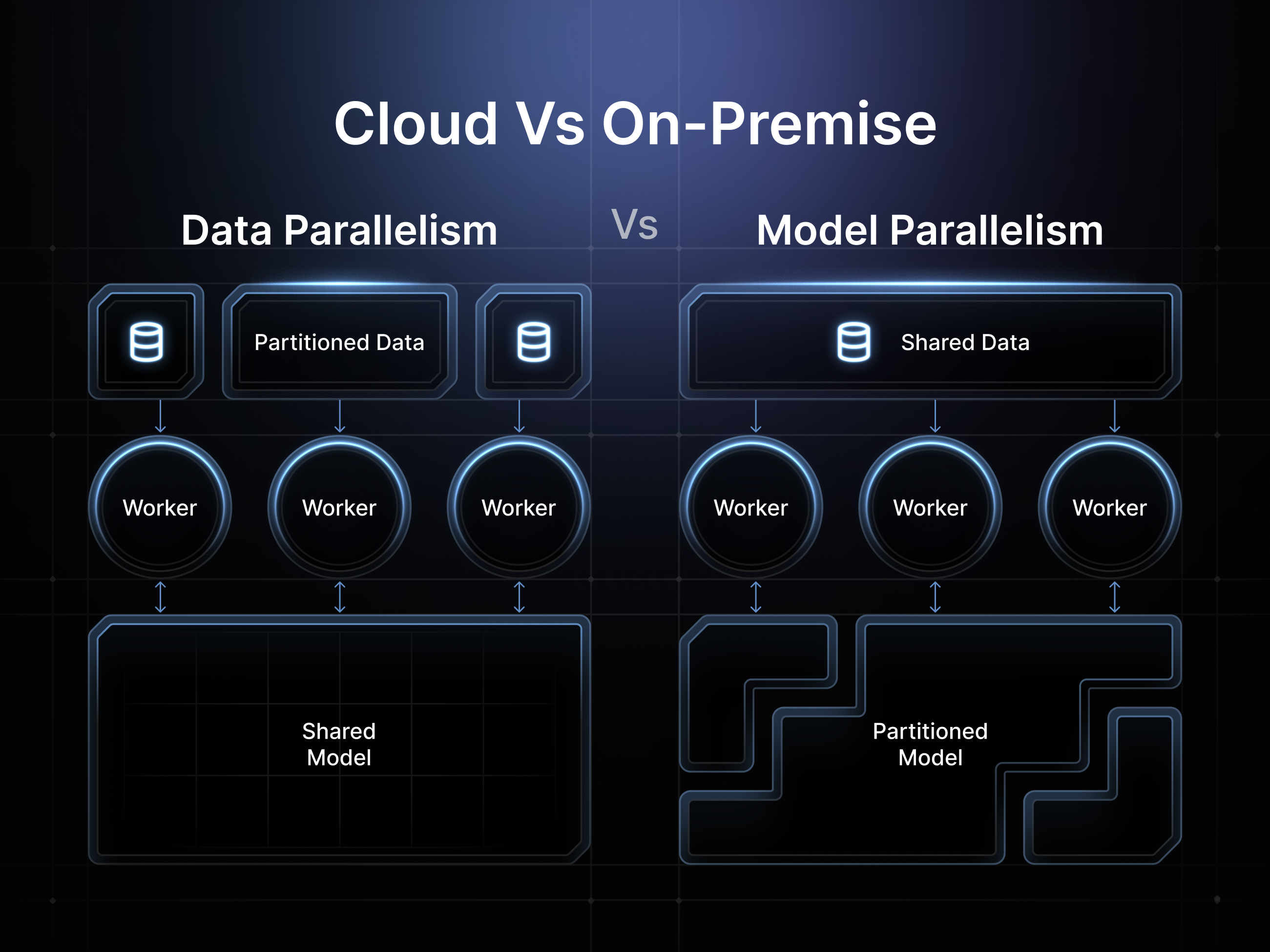
Instead of relying on large monolithic cloud providers or expensive, siloed on-premise operations, distributed ML infrastructure leverages a network of independent nodes. As a result, providers like io.net can offer cloud-like scalability through a massive supply of enterprise-grade resources but retain operational simplicity without demanding high fees or vendor premium lock-ins, all the while improving security and eliminating single points of failure from the equation.
Key Components of ML Infrastructure
The development of distributed ML infrastructure balances several interconnected layers across the entire tech stack. The system encompasses the base physical hardware components, internal software, data infrastructure, model management, and workflow orchestration. Each part plays an integral role in the success of the larger infrastructure.
Hardware Components
At the foundational layer of any ML infrastructure is the computational hardware that everything else is built on top of. Distributed architecture platforms like io.net aggregate existing underutilized hardware resources and provide access to over 30k verified GPUs across 130+ countries, even the highly sought-after enterprise-grade H100s.
Compared to building out an independent on-site data centre that could cost billions or going through traditional Big Tech cloud providers that often have weeks-long wait times for H100s, a distributed architecture provides an attractive, inexpensive, and accessible alternative. io.cloud leverages this new distributed model to allow users to immediately deploy GPU clusters without lock-in contracts or waitlists at a fraction of the price of the traditional cloud providers.
Software Components
The integration of robust open-source software is key to the accessibility of distributed architecture. That is why the io.net platform is natively built on top of the ML framework, ray.io. Utilizing an open-source framework like this allows for the seamless integration of existing ML workflows while providing enterprise-grade orchestration capabilities.
This integration allows teams to leverage familiar frameworks like PyTorch, TensorFlow, and Anyscale without needing to modify their existing codebases. As a result, the io.net platform can easily support comprehensive ML requirements like preprocessing, distributed training, hyperparameter tuning, reinforcement learning, and model serving.
Data Infrastructure
ML infrastructure is only as efficient and cost-effective as the distribution of its data. This is where the difference between distributed architecture and its Big Tech cloud competitors becomes apparent. io.net’s distributed architecture enables parallel data processing across multiple nodes, which significantly improves the performance and accelerates the preprocessing of training workflows. The platform’s mesh network topology improves network security while creating optimized data flow between nodes, while also maintaining strict reliability standards.
Model Management
The accessibility of multiple AI open-source models in a distributed architecture allows teams to experiment and evaluate the optimal route between models without changing integrations. This is a significant upgrade on Big Tech cloud providers that can often force applications to commit to a single model per round of testing. io.intelligence excels at this through its unified single API model management approach that grants users access to 25+ open-source models at any moment.
Workflow Orchestration
Tying together the entire workload across distributed architectures is automated ML workflow orchestration. Its role is to navigate and optimize routes for data processing, scheduling, and fault tolerance while supporting processes like preprocessing, distributed and reinforced learning, hyperparameter tuning, and model serving. The use of automated orchestration allows for the most efficient use of resources while eliminating traditional infrastructure pipeline bottlenecks that are hampering legacy cloud providers.
Cost-Effective ML Infrastructure Solutions
Independent dedicated on-premise ML infrastructure is prohibitively expensive for most projects. Historically, this has pushed applications into sole reliance on Big Tech cloud providers’ premium pricing models. This asymmetrical relationship has allowed Big Tech to artificially inflate costs, creating barriers to entry and dramatically reducing the runway of many smaller projects.
Distributed architecture turns this narrative on its head and offers substantial cost savings and increased flexibility. Consider that the deployment costs on AWS H100s are $12.29/hr. That means running an average of one hundred H100 GPUs per month will cost an AI application in excess of ~$300k/month compared to running the same H100s on io.cloud, which costs $2.19/hr and only ~$30k/month. These cost savings are not insignificant. By reducing the operating costs of ML applications by up to 90% teams can redeploy resources to run more experiments, train larger models, and maintain their development velocity. More innovation for less.
These cost savings are not solely from overcoming aggressive pricing practices of the entrenched interests of Big Tech cloud providers. There is a significant efficiency gain that distributed architecture obtains from its decentralized geographic distribution of GPUs. The cloud approach requires the ongoing maintenance of static geolocked data centers with the continued funding of infrastructure needed to support them. Distributed architecture has no such expenses, and with its over 30k verified GPUs distributed across over 130 countries, it allows for these savings to be passed on to the end user. Additionally, teams can further reduce their costs by selecting resources based on their regional proximity to data sources or pricing variations among an open marketplace of suppliers.
Scaling ML Infrastructure for Production
A distinct advantage that distributed ML infrastructure has over its Big Tech cloud competitors is its ability to dynamically scale to meet demand. Traditional Big Tech infrastructure has relied on the inefficient over-provisioning of resources to handle the maximum peak demand of applications. This leads to unnecessary waste during periods of lower utilization and requires applications to pay for constant peak-demand rates throughout their run time to ensure the model never fails.
By comparison, distributed platforms like io.net allow ML teams to scale from a single GPU to massive clusters instantly with auto-scaling infrastructure that fluctuates with the workload. Through leveraging sophisticated load-balancing mechanisms across its entire global mesh network architecture, io.net can minimize latency through optimizing the most efficient paths for data and resource passage.
When scaling applications to enterprise levels, the optimal route navigation of resources and dynamic scaling features becomes critically important for reducing bottlenecks and bloated, inefficient costs accrued during periods of lower off-peak demand.
ML Infrastructure for Distributed Computing
Decentralized ML infrastructure is ideal for distributed computing and outperforms Big Tech cloud monopolies for many of the reasons outlined above. However, the synergistic tech stack that exists within distributed models becomes even more apparent when looking at its enhanced fault tolerance capabilities.
Through leveraging the power of a collection of independent nodes, distributed systems can create robust, redundancy-enhanced networks. Where Big Tech cloud providers concentrate resources into massive data centers, creating a large attack surface and a single point of failure, a distributed architecture can remain operational when any individual node fails.
These single points of failure are becoming increasingly important in the age of AI. Any amount of downtime can significantly impact the overall efficacy of a model, but more importantly, if there is a breach in security, teams building models with highly sensitive data sources could see their data leaked or exposed. The loss of proprietary information or the doxing of sensitive information could leave teams vulnerable to attack themselves. Distributed models with enhanced fault tolerance prevent these attacks from occurring through the creation of a more robust, secure infrastructure. Within distributed models, teams can also encrypt data sources they wish to keep private and inaccessible to other models and applications.
The importance of redundant network pathways is that they primarily create a more secure and robust network, but also allow for the continued flow of resources across the network in the event of any node outage. io.net’s mesh network architecture is an excellent example of distributed ML architecture’s fault tolerance in action.
Additionally, distributed networks' enhanced fault tolerance is a significant reason for their ease of scalability. Nodes can be redirected during outages, but can also be easily added or removed as an application's user base expands for ease of scalability. This dynamic scalability and enhanced fault tolerance create a powerful combination that allows for a more reliable, adaptable, and consistent architecture, allowing for projects to scale effectively with peace of mind.
Why is ML Infrastructure Important?
The simple and most obvious answer to why ML infrastructure and the expansion of distributed networks are important is because of the supply-demand imbalance currently hindering the industry’s continued development. The surging demand for AI ML model training and inference workloads also creates less of an incentive for Big Tech cloud providers to solve the supply issues. These providers currently only have between 10-15 exaFLOPs of GPU compute supply for an industry needing 20-25 exaFLOPs. Still, even if these providers were able to scale their operations to meet current demand, they have an imbalance in power that allows them to exploit ML applications through artificially restricting the supply and charging excessive vendor lock-ins. This supply-demand imbalance primarily impacts smaller operations that could be driving the most innovation disproportionately by creating financial barriers to entry and delayed deployments of critical infrastructure.
However, the importance of creating an alternative ML infrastructure to the status quo extends beyond the financial impacts of the current supply-demand imbalances. More advanced modern AI applications require infrastructure that is flexible, easily scalable, and able to adapt to varying workload demands without excessive overhead and delayed deployments.
The distributed model addresses these challenges by providing democratic access to computational resources. Instead of requiring massive upfront investments or long-term contracts, teams can access GPU clusters on demand with transparent, competitive pricing.
Examples of ML Infrastructure in Practice
The io.net platform is a prime example of ML infrastructure in action. Its offerings include batch inference and model serving, parallel training workflows, hyperparameter optimization, and reinforced learning models.
Batch Inference and Model Serving
Decentralized ML models can easily perform inference on incoming data batches in real time by parallelizing and exporting model weights and architecture parameters to a shared object store. This allows teams to build out their workflows across a fully distributed network of GPUs. io.intelligence expands upon this by enabling cost-efficient inference through its unified API, which can deliver up to an additional 70% in cost savings compared to Big Tech cloud providers.

Parallel Training Workflows
Memory constraints of CPU and GPUs, combined with the sequential processing found in cloud providers, create massive bottlenecks when training ML models on single devices. Distributed networks like io.net eliminate these constraints by enabling parallel processing across data and commands, which allows teams to more easily scale their training workloads across an entire network of thousands of GPUs simultaneously.
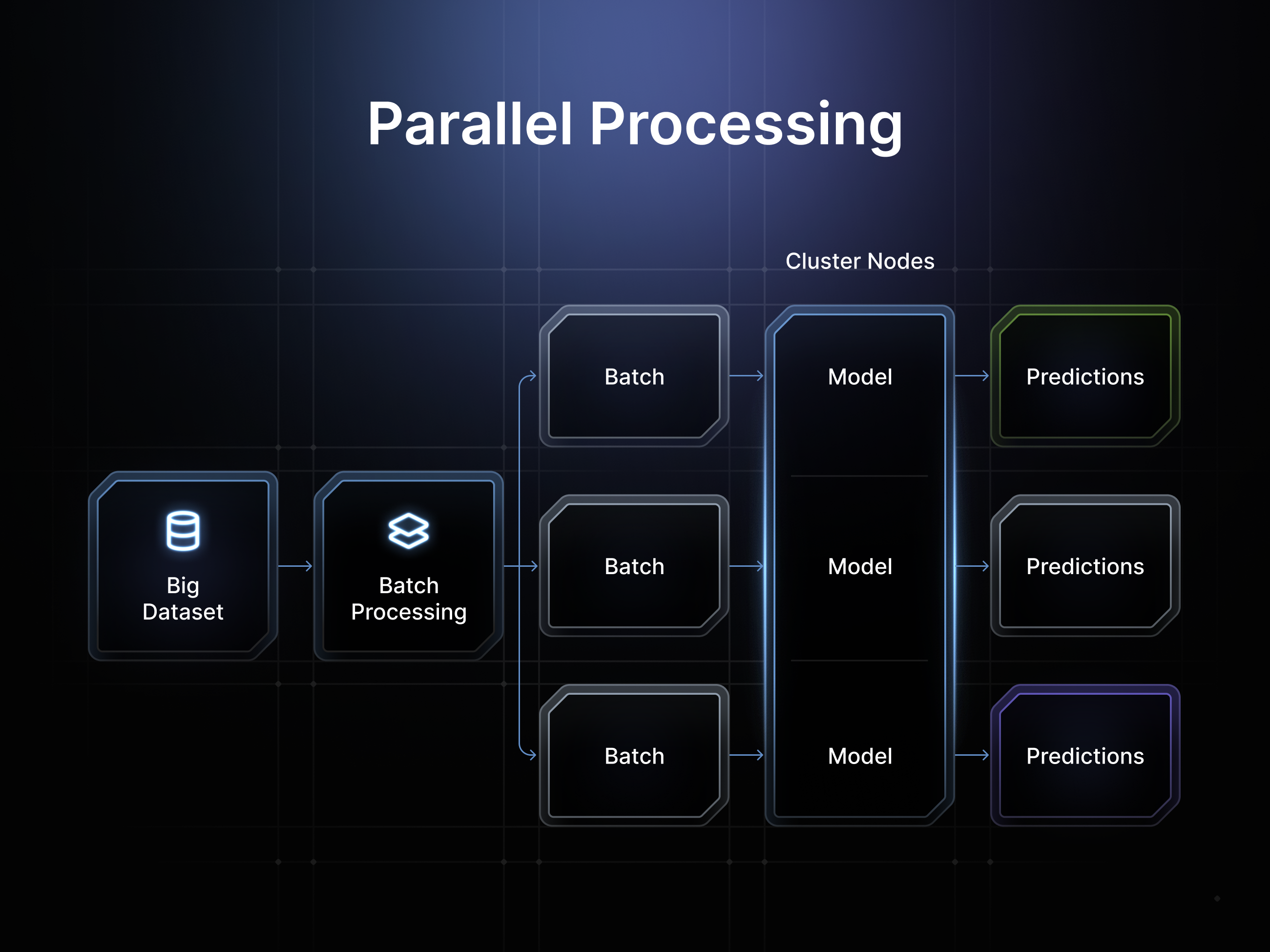
Hyperparameter Optimization
Hyperparameter tuning experiments are inherently parallel, making them ideal for distributed networks. io.net leverages distributed computing libraries with advanced hyperparameter tuning for checkpointing the best result, optimizing scheduling, and specifying search patterns. This parallel approach dramatically reduces experimentation time while improving model performance.
Reinforcement Learning
Open-source learning libraries complement decentralized ML infrastructure by providing accessible data for ongoing reinforcement learning workloads. io.net leverages this dynamic to support production-level workloads across its integrated APIs. These complex reinforcement learning experiments would be prohibitively expensive if run on Big Tech cloud providers.
The Future of ML Infrastructure
Decentralized ML infrastructure represents an evolution of AI ML training. A paradigm shift away from the centralized control of Big Tech cloud monopolies towards a more democratic, efficient, and scalable future. Platforms like io.net are leading the charge, providing applications and teams access to enterprise-grade computational resources without the financial and time constraints that cloud providers have artificially imposed.
The financial cost-saving benefits of transitioning to a distributed ML infrastructure are apparent on io.net, where applications on average see a 70% cost reduction vs AWS and Azure for H100 training workloads. Combined with the improved fault tolerance, security enhancements, and ease of access to enterprise-grade GPU clusters that can be deployed in under two minutes, it is clear just how much decentralized ML infrastructure outperforms Big Tech cloud monopolies.
For ML infrastructure engineers ready to explore distributed computing advantages, io.cloud provides immediate access to over 30,000 verified GPUs across 130+ countries, while io.intelligence offers unified model management and inference capabilities. The future of AI infrastructure is distributed, democratic, and available now.


.svg)



.png)